How to structure BGV/IDV operations for defensible, SLA-driven exception handling
This framework translates 62 domain questions into three actionable operational lenses to help organizations design scalable BGV/IDV programs. Each lens maps questions to a stable discipline, enabling reusable insights, auditable decision trails, and practical signals for day-to-day operations.
Is your operation showing these patterns?
- Queue aging spikes during peak hiring periods
- Escalation backlog grows beyond target SLA
- Reviewer touches per case remain high despite tooling
- Dispute cycle time climbs after policy changes
- Upstream data source outages occur with increasing frequency
- Audit findings reveal inconsistent evidence logging
Operational Framework & FAQ
Operational workflow governance, SLA management, and escalation controls
Designs end-to-end verification workflows that control queue states, SLAs, and escalation rules for predictable hiring outcomes. Includes runbooks for peak periods, routing logic, and capacity planning to prevent SLA breaches.
How do your BGV case queues work (new/in-progress/awaiting info/exceptions) so we don’t miss SLAs during spikes?
C1856 Queue structure for SLA control — In employee background verification (BGV) operations, how does your case management workflow structure queues (new, in-progress, awaiting-candidate, awaiting-source, exception) to prevent SLA breaches during hiring spikes?
Employee background verification case management workflows structure queues by status so that new, in-progress, awaiting-candidate, awaiting-source, and exception cases are visible and prioritized during hiring spikes. This segmentation helps operations teams prevent SLA breaches by focusing attention and resources where delay risk is highest.
New cases are typically triaged into in-progress queues where reviewers perform initial checks. Awaiting-candidate queues hold cases where forms, documents, or consent are pending, while awaiting-source queues capture checks dependent on external entities such as employers, education boards, or courts. Exception queues contain cases with discrepancies or complex findings that require specialist review before closure.
During volume surges, operations managers track queue sizes and case aging within each category and adjust staffing, routing, or escalation rules accordingly. Dashboards highlight pending actions and turnaround performance, and alerts flag cases that remain in a given status beyond configured thresholds so they can be escalated or rebalanced.
Priority rules can also factor in role criticality, risk tier, or regulatory requirements so that high-impact positions or mandated checks receive preferential handling even when queues are long. This structured queue design, combined with monitoring and explicit prioritization criteria, allows verification programs to absorb hiring spikes while maintaining turnaround and compliance commitments.
How do you define and enforce escalation SLAs for common BGV exceptions like mismatches or source delays?
C1858 Escalation SLAs by exception type — In employee background screening workflows, how are escalation SLAs defined and enforced for common exception types like address mismatch, employer non-response, education issuer delays, and identity document ambiguity?
Escalation SLAs in employee background screening workflows are defined by categorizing exception types and specifying time-bound steps, ownership, and fallback actions for each category. These SLAs are then enforced by workflow rules and monitoring so that address mismatches, employer non-response, education delays, and identity document ambiguities do not quietly extend turnaround times.
Organizations typically group exceptions by risk and complexity. Lower-risk issues like some address discrepancies may allow longer candidate-response windows, whereas identity document ambiguity or potential fraud indicators trigger faster escalation to senior reviewers. Client-specific policies and role criticality further shape timelines and required actions for each exception type.
Case management systems implement these SLAs by moving cases into dedicated escalation queues when thresholds are crossed and notifying responsible users via alerts and dashboards. Each escalation step, contact attempt, and decision is recorded in the case history, creating an audit trail that supports both internal oversight and external reviews.
Aggregated monitoring of exception volumes and aging by category helps operations and Compliance identify where SLAs are consistently missed and whether policy adjustments, staffing changes, or alternative data sources are needed. This structured escalation design keeps exception handling predictable and defensible while aligning with hiring speed and regulatory expectations.
How do you route BGV cases (round-robin vs skill/risk-based), and how do we see impact on escalations and closure rates?
C1863 Case routing and performance impact — In employee background verification workflows, what case assignment logic is supported (round-robin, skill-based routing, risk-tier routing), and how do you measure its impact on escalation ratio and case closure rate?
Employee background verification workflows use case assignment logic as an operational control, but the specific mechanisms depend on the maturity of the platform and the organization. The most common patterns are simple round-robin allocation, skill-based routing by check type or geography, and policy-driven routing that prioritizes higher-risk or more complex cases for experienced reviewers.
Round-robin distribution offers straightforward load balancing but does not account for reviewer expertise, which can raise escalation ratios when complex criminal record checks, court record digitization tasks, or multi-jurisdictional cases land with less experienced staff. Skill-based routing attempts to mitigate this by directing specific workstreams, such as criminal / court checks or address verification exceptions, to teams trained for those checks. Some organizations further layer basic risk-based rules, for example sending cases with multiple discrepancies or sensitive roles to senior analysts, even without a formal scoring engine.
To understand the impact of these routing strategies, mature programs track queue-level and reviewer-level metrics such as escalation ratio, case closure rate, turnaround time distribution, and reviewer productivity. They often run controlled pilots when changing assignment rules and compare metrics before and after the change. More granular routing can reduce unnecessary escalations and improve closure quality, but it introduces trade-offs around complexity, training requirements, and the risk of new bottlenecks if certain skill queues become overloaded. In lower-maturity environments where platforms support only basic routing, organizations may approximate skill-based assignment through work instructions and manual queue management while still monitoring the same KPIs.
What’s the playbook when a source is down or unresponsive, and how do you update HR on revised ETAs?
C1864 Playbook for source unavailability — In employee BGV programs, what is the operational playbook when an upstream data source fails (court registry downtime, employer unreachable, education board delay), and how is that exception communicated to HR with revised ETAs?
When an upstream data source fails in employee background verification operations, effective programs treat the event as a defined exception with clear retry, fallback, and communication rules rather than an ad-hoc disruption. Typical triggers include court registry downtime, unreachable employers, or delayed responses from education boards or other issuers.
Operationally, the affected check is tagged with a specific exception reason and separated from routine escalations. For registries or court databases, operations teams usually pause that component and apply documented re-attempt schedules until the source becomes available again. For employer or institution verifications, standard practice includes multiple contact attempts and channels over a defined period, after which the check may be closed as “unable to verify” or similar, according to the organization’s risk policy. Any consideration of alternative verification methods or sources must remain within consent, purpose limitation, and other regulatory obligations described in the verification policy.
Communication with HR, Risk, and other stakeholders focuses on transparency and risk decisions. Organizations reflect source-level outages or delays in status views and periodic reports, and they highlight which cases are affected and how expected turnaround time is impacted, even if ETAs are estimated manually. For roles where unresolved checks are critical, operations teams often seek explicit HR or Compliance decisions on whether to delay onboarding, issue conditional offers, or accept defined risk, and they record those decisions for audit. A common failure mode is blending systemic source downtime into generic case delays, which obscures root causes, complicates SLA discussions, and weakens audit narratives.
How do you track dispute cycle time, and what levers help reduce it without compromising verification quality?
C1868 Dispute cycle time measurement — In background verification operations, how do you measure and report dispute cycle time (from candidate challenge to resolution) and what operational levers reduce it without weakening verification depth?
Background verification operations measure dispute cycle time by capturing the period from when a candidate or employee raises a challenge to when a final decision is recorded and communicated. This metric serves as an indicator of both governance quality and operational responsiveness, especially where privacy and fairness obligations require timely redressal.
In structured workflows, disputes are logged as explicit case events linked to specific checks such as employment, education, criminal or court records, or address verification. Systems or teams record the start date, track steps such as additional evidence gathering, re-verification with issuers, and internal review, and then mark the case as resolved when an updated outcome is confirmed and shared with HR and the individual. Even when these steps are managed via email or tickets rather than a dedicated tool, organizations can still calculate average dispute cycle times from timestamps and include them in periodic reporting.
Reducing dispute cycle time without weakening verification depth depends on standardization rather than shortcuts. Effective levers include predefined re-verification playbooks for common dispute types, clear communication templates that tell candidates what additional documents are useful, and routing complex disputes to experienced reviewers instead of general queues. Organizations that treat disputes as formal workflow types, monitor their turnaround alongside escalation ratios, and feed lessons into data quality and communication improvements tend to achieve faster, more defensible resolutions than those that handle each case ad hoc.
What dashboards and alerts do you provide for aging queues, SLA risk, escalation backlog, and reviewer productivity?
C1869 Operational dashboards and alerts — In employee BGV operations, what dashboards exist for queue aging, SLA-at-risk cases, escalation backlog, and reviewer productivity, and can alerts be pushed to HR and Compliance stakeholders?
In employee background verification operations, dashboards for queue aging, SLA-at-risk cases, escalation backlog, and reviewer productivity are widely used to give HR, Compliance, and Operations real-time visibility into screening workflows. These views help identify bottlenecks, prioritize critical cases, and monitor whether verification activities are on track against agreed SLAs.
Common dashboard elements include counts of cases by status and age, tiles for categories such as “candidate login expired,” “insufficient cases,” “go-ahead pending,” and “sign-off pending,” and charts for forms pending at the candidate side and TAT closure percentages. Reviewer productivity and escalation backlogs are often tracked through case volumes handled per reviewer, numbers of cases in exception queues, and distributions of completed cases by severity or risk level. Such consolidated views allow operations leaders to rebalance workloads and inform HR when specific cohorts of candidates are stuck.
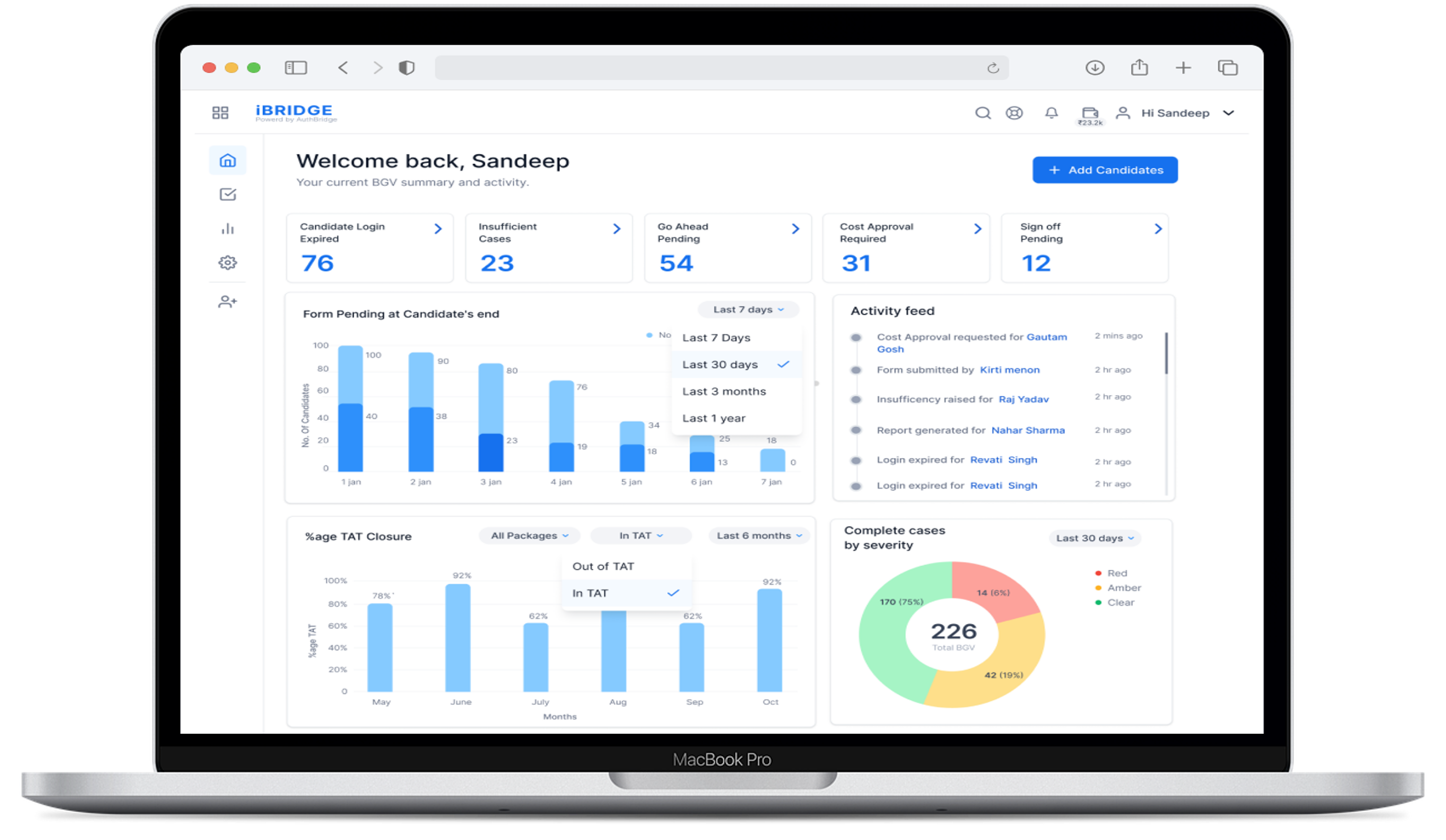
Alerting mechanisms range from simple email digests or on-screen notifications about aging or SLA-at-risk queues to more configurable thresholds that, when available, can push alerts to HR, Compliance, or vendor management when backlog or severity indicators cross defined limits. A recurring failure mode is treating dashboards purely as informational, without linking them to concrete playbooks for queue reprioritization, exception handling, or policy review. More mature programs tie dashboard insights to operational actions and governance forums, using the same metrics in QBRs and internal audit discussions.
Can we set up multi-level approvals for exceptions (HR risk acceptance, Compliance policy deviation) with a clear audit trail?
C1870 Multi-level exception approvals — In employee background verification workflows, how do you support multi-level approvals for exceptions (e.g., HR approval for risk acceptance, Compliance approval for policy deviation), and what is the audit trail for each approval?
Employee background verification workflows handle multi-level approvals for exceptions by making risk acceptance and policy deviation decisions explicit, role-based, and auditable rather than informal. The operational goal is to ensure that any decision to proceed despite incomplete verification or adverse findings is clearly attributed to accountable stakeholders such as HR and Compliance.
When an exception exceeds routine rules—such as unresolved employment for a sensitive role or a criminal or court record that may still be considered hiring-eligible—the case is flagged and routed into an exception decision path. Depending on organizational design and tooling, this path may involve sequential or parallel approvals. HR may first assess business need and candidate context, and Compliance or Risk then evaluates policy fit, regulatory exposure, and consistency with prior decisions. Even where workflow engines are limited, organizations can still require that each approver records a decision, rationale, and date in a central case log rather than via scattered emails.
The resulting audit trail should capture which exceptions were raised, which risk tiers they corresponded to, who approved or rejected them, and the stated reasons. These records support internal audit, regulator queries, and fairness reviews by showing that similar cases were treated under the same policy logic. A common failure mode is relying on informal approvals that are not tied back to the case record, which weakens explainability and makes it difficult to demonstrate compliance with purpose limitation and non-discrimination principles. More mature programs therefore embed multi-level exception approvals directly into case management and use these data points to refine both policy and training.
What staffing assumptions do you recommend (cases per reviewer hour, escalation ratio), and how do they vary by check bundle?
C1872 Staffing model by check bundle — In employee BGV operations, what staffing model assumptions do you recommend (cases per reviewer hour, expected escalation ratio) and how do those assumptions change for different check bundles like CRC+AV versus employment+education?
Employee background verification operations typically build staffing models around two core parameters: expected cases per reviewer hour and escalation ratios for each check bundle. However, there is no universal benchmark, because throughput is shaped by check complexity, data source quality, automation maturity, and regulatory or internal requirements on who may perform certain reviews.
In practice, simpler and more standardized checks with stronger automation support, such as digitally enabled criminal record or basic address verification where court records and address data are well-structured, tend to permit higher case volumes per reviewer hour. Bundles that rely on manual outreach or nuanced judgment, such as employment and education verification through calls and emails, generally yield lower throughput and higher escalation ratios. Jurisdictional realities matter; where courts or institutions lack digitization, even CRC or AV components can become labor-intensive, reducing reviewer capacity.
Mature programs therefore use pilots to derive organization-specific assumptions. They measure reviewer productivity by check type, monitor escalation ratios and case closure rates, and observe how throughput changes when discrepancy rates are higher or when senior reviewers are required for certain decisions, as in regulated BFSI contexts. Staffing models are then differentiated for bundles such as CRC+AV versus employment+education and stress-tested for hiring surges. A common failure mode is importing generic vendor or industry numbers without adjusting for local data quality, candidate demographics, or governance constraints, which leads to misaligned headcount and SLA risk.
What training is needed for reviewers and HR ops, and how long until they’re productive after go-live?
C1873 Training effort and proficiency time — In employee BGV workflows, what training and certification is required for reviewers and HR ops users, and what is the expected time-to-proficiency to avoid productivity drops at go-live?
In employee background verification workflows, training for reviewers and HR operations users is organized around three themes: understanding verification policies and risk tiers, operating the case management and dashboard tools, and documenting decisions in a way that supports audits, disputes, and regulatory reviews. There is no single industry-wide certification standard, so organizations usually define their own internal training and competency criteria, with regulated sectors tending toward more formal programs.
Reviewers require detailed instruction on each check type, including employment, education, address, and criminal or court records. They learn what constitutes acceptable evidence, how to handle incomplete or conflicting responses, when to escalate, and how to apply privacy, consent, and data minimization principles in day-to-day work. HR operations users focus on creating and tracking cases, interpreting status dashboards, handling candidate communications, and coordinating with HR, Compliance, and vendors. Written SOPs and playbooks for common scenarios help standardize decisions and reduce escalation ratios.
Time-to-proficiency varies by prior experience, platform ergonomics, and check complexity, so many programs treat the first weeks after go-live as a controlled ramp-up period. During this phase, organizations expect lower reviewer productivity and more supervision of edge cases, using metrics such as escalation ratio, case closure rate, and error rates to gauge when users have reached steady-state performance. A recurring failure mode is underestimating the training needed for complex or judgment-heavy checks, which can lead to SLA misses and inconsistent risk decisions early in the rollout.
If a case gets reopened due to new evidence, how do you keep versioning and audit trail intact?
C1874 Reopened cases and version control — In background verification operations, how do you handle re-opened cases (new evidence received, late employer response) without breaking chain-of-custody, versioning, and earlier decision rationale?
In background verification operations, re-opened cases are best handled as additional lifecycle states of the original case, with careful preservation of chain-of-custody, version history, and decision rationale. Typical triggers include late responses from employers or institutions, candidate-submitted documents that address earlier gaps, or new legal or court information becoming available.
Operationally, the re-open action should be explicitly logged, including who initiated it and for what reason, and new evidence should be appended to the existing case record rather than creating an unlinked duplicate. Prior conclusions are retained as historical versions, and reviewers reassess only the affected checks in light of the new information. Updated outcomes are then recorded with clear commentary on what changed and why, so that an auditor can follow the decision evolution step by step. Where tooling is limited, organizations approximate this approach through disciplined record-keeping conventions to avoid overwriting past data.
This versioned handling is important for legal defensibility, internal audits, and dispute resolution, because it shows that the organization responds to new evidence in a structured way rather than retroactively editing history. It also provides inputs for commercial and operational analysis, such as understanding rework effort and how often late information changes outcomes. In regulated or highly governed environments, re-opened cases may additionally require specific approvals or notifications when prior adverse decisions are revised, reinforcing the need to integrate re-open workflows with existing exception and approval processes.
How do operational misses and exceptions translate into SLA credits or recheck policies so Finance gets predictable cost outcomes?
C1875 Commercial accountability for exceptions — In employee BGV operations, how are operational exceptions translated into commercial accountability (SLA credits, recheck policies, rework cost visibility) so Finance sees predictable spend impacts?
In employee background verification operations, converting operational exceptions into commercial accountability means making sure that SLA definitions, recheck policies, and rework tracking are explicitly connected to how spend is measured and reported. Finance and Procurement look for predictable visibility into how delays, errors, and exceptional effort influence total cost of verification rather than learning about these effects only anecdotally.
Organizations typically start by defining which operational metrics are commercially relevant, such as turnaround time SLAs for specific check types, rates of rechecks, and volumes of rework attributable to different causes. Contracts or internal cost models then describe how these events are treated, for example whether repeated SLA misses trigger discussions or remedies, whether certain rechecks are chargeable or included, and how pricing adjusts when actual verification patterns deviate from assumptions. The exact mechanisms—credits, free rechecks, or volume adjustments—are negotiation choices rather than industry standards.
To enable this linkage in practice, mature programs ensure that case management and reporting can differentiate first-pass verifications from rework and can tag likely root causes, such as vendor-side issues versus poor candidate inputs. Periodic reports then translate these operational patterns into financial terms, helping Finance see how exception volumes affect effective cost-per-verification and whether the commercial model remains aligned with risk appetite and SLA performance. A common failure mode is not capturing rework and exceptions in a structured way, which makes it difficult to attribute costs, manage vendor relationships, or forecast budget with confidence.
If our BGV queues spike and SLAs start slipping, who gets alerted, what do you deprioritize, and how do you document any risk acceptance?
C1878 Surge playbook and risk acceptance — In employee background verification (BGV) operations, what happens operationally when the verification queue explodes during a hiring surge and escalation SLAs start failing—who gets alerted, what gets deprioritized, and how is risk acceptance documented?
When verification queues spike during a hiring surge and escalation SLAs start to fail, effective employee background verification operations follow a predefined overload playbook that clarifies who is alerted, which activities can be reprioritized, and how any risk acceptance is documented. Treating surges as a planned-for scenario rather than a surprise helps preserve both hiring throughput and compliance defensibility.
In more instrumented setups, metrics such as queue aging, SLA-at-risk counts, and reviewer utilization trigger alerts to verification program managers and HR leadership when defined thresholds are crossed. In less automated environments, similar signals may surface via periodic reports or manual monitoring. Once a surge is recognized, leaders consider levers including temporary staff reallocation, overtime, or selective adjustment of routing so that the highest-risk roles and checks continue to receive priority. In regulated or safety-critical roles, core checks typically remain non-negotiable even under stress, so any deprioritization focuses on lower-impact checks or less urgent hiring segments.
Risk acceptance decisions and deviations from normal policy should be explicitly recorded. Organizations log which checks or cohorts were delayed, who approved the deviation (for example HR and Compliance), the rationale, and the intended timeframe for returning to standard practice. Some also use these episodes as inputs to longer-term capacity planning by analyzing how often surge thresholds are breached and how much additional capacity or automation would be needed to avoid future overload. A common failure mode is improvising under pressure without documentation, which later undermines auditability and makes it hard to learn from the incident.
What usually drives high escalations in real BGV operations, and what fixes have actually worked for your customers?
C1880 Escalation drivers and mitigations — In employee BGV operations, what are the most common failure modes that cause high escalation ratios (source delays, poor candidate data, workflow misconfiguration), and what concrete mitigations have you seen work in production?
In employee background verification operations, high escalation ratios most often arise from slow or inconsistent responses from external sources, low-quality or incomplete candidate data, and workflow or policy configurations that generate more exceptions than necessary. Identifying which factor is dominant in a given program is crucial for targeting remediation.
Source-side issues occur when courts, police, employers, or education boards respond slowly or with partial information, especially where digitization is limited. These conditions push many cases into pending and follow-up states that require manual oversight. Candidate-side issues include inaccurate identity details, incomplete addresses, or inconsistent employment and education histories, all of which trigger clarifications and re-verification. Workflow-related drivers include overly strict validation rules, mismatch between verification depth and role criticality, or routing logic that sends routine anomalies into high-touch queues instead of allowing streamlined resolution.
Mitigations that have proven effective in production programs focus on both inputs and process design. Upfront, organizations improve candidate UX and instructions to reduce data errors and may deploy stronger identity and document validation in early steps. Within operations, they tune validation thresholds and routing based on observed escalation patterns, calibrate check depth to risk tiers, and implement standardized re-verification playbooks and communication templates. From a governance perspective, they monitor escalation ratio, turnaround time, hit rate, and reviewer productivity at the check-type level, then iterate policies and workflows based on these KPIs rather than relying on one-off adjustments. Any consideration of alternative data sources or verification methods is constrained by consent scope, purpose limitation, and applicable regulations and is documented accordingly.
What’s the worst TAT/backlog you’ve seen in production, and what controls kept it from turning into a full SLA meltdown?
C1883 Worst-case backlog control proof — In employee BGV and IDV operations, what is your worst-case TAT and escalation backlog experience in production, and what operational controls (routing, throttling, staffing surge) prevented a complete SLA collapse?
In employee BGV and IDV operations, worst-case TAT and escalation backlogs usually emerge when verification demand or manual-review volume spikes faster than capacity. Organizations limit SLA damage by predefining routing priorities, constraining intake when downstream capacity is saturated, and activating temporary capacity or simplification measures under governance.
Many programs use risk-tiered routing so that critical roles or time-bound hires are processed ahead of lower-risk cases when queues build up. In more advanced setups, API gateways or workflow controls slow or batch new case intake when external data sources or internal reviewers are under strain, which prevents the entire case inventory from drifting out of SLA at once. Where such technical throttling is not available, teams approximate the effect through scheduling controls, intake caps agreed with HR, or redirecting specific check types to spread load.
Backlog controls extend beyond routing. Operations managers monitor backlog size, escalation ratios, and TAT distributions by check type, using this data to trigger temporary responses such as reallocating cross-trained reviewers to the most delayed checks or staggering lower-priority re-screens. In some environments there is limited ability to add surge staff, so teams instead simplify exception paths within policy, or temporarily shift from deep to risk-tiered verification while clearly marking affected checks as pending or partial. The combination of visible metrics, explicit prioritization rules, and documented temporary measures helps prevent a complete SLA collapse, even though some cases will inevitably breach targets during severe events.
If disputes spike after a policy change, do dispute SLAs or costs change, and how do you keep it predictable for Finance?
C1887 Dispute spikes and cost predictability — In employee BGV operations, what is the operational and commercial outcome when disputes spike (for example after a policy change)—do dispute SLAs change, do costs increase, and how is this kept predictable for Finance?
When disputes spike in employee BGV operations, the immediate operational effect is more rework, longer effective TAT for disputed cases, and a heavier escalation load. The commercial consequence is pressure on productivity and unit economics if the extra work is not bounded by predefined dispute workflows, SLAs, and volume assumptions.
Operationally, mature programs treat a dispute as a defined case state or linked workflow, with ownership, SLA targets, and evidence requirements set in advance. Even if the technical platform does not have a dedicated “dispute” state, operations designate such cases in tracking sheets or tags so they can measure dispute volume, average resolution time, and escalation ratios when a policy change occurs. This visibility allows managers to temporarily reassign staff, refine standard responses, or adjust how results are communicated to reduce avoidable disputes.
Commercial predictability comes from agreeing upfront how disputes are handled within service and pricing models. Organizations clarify whether dispute handling is included in per-check pricing, whether any categories of disputes are billable, and what resolution timelines are realistic. When a policy change structurally increases disputes, stakeholders can either agree on temporary SLA relaxations, add capacity to keep within existing SLAs, or revisit scope and pricing at the next review point. Finance gains predictability when dispute rates, handling effort, and any associated costs are captured as part of regular KPI and budgeting cycles rather than treated as ad-hoc exceptions.
If an auditor asks for sampled exception cases, how fast can you produce the full chain-of-custody and action timeline per case?
C1889 Audit sampling readiness for exceptions — In employee BGV operations, if a regulator or internal audit asks for a sampled set of exception cases, how quickly can you produce complete chain-of-custody, reviewer actions, and escalation timestamps for each case?
In employee BGV operations, organizations can respond quickly to regulator or internal audit requests for sampled exception cases when every meaningful action in the verification workflow is logged against the case and can be exported as a coherent history. The more that exception handling is executed inside a case management system with activity tracking, the less time is needed later to reconstruct chain-of-custody.
Mature programs ensure that exception triggers, reviewer assignments, status changes, evidence uploads, and escalations each generate structured log entries with timestamps and user identifiers. These entries are linked to a unique case ID, so an auditor’s sample list can be turned into per-case “history reports” or audit bundles containing actions, decisions, and attachments. Standard report templates or export functions for “full case history” further reduce turnaround, making the main gating factor internal approval to share rather than technical assembly.
Where tooling is less advanced, organizations approximate the same outcome through disciplined use of case notes, centralized storage of evidence, and consistent referencing of case IDs in email or ticketing systems. In such environments, producing a complete chain-of-custody for sampled exception cases may take longer and require manual compilation, so teams plan for that in audit playbooks. They define roles responsible for pulling records, set internal response targets that meet expected audit timelines, and periodically rehearse the process to ensure that even with more manual effort, exception histories remain retrievable and defensible.
When a check returns ‘can’t verify,’ what’s the decision tree, who approves, and how do you keep HR decisions consistent?
C1890 Cannot-verify decision tree governance — In employee screening operations, how do you handle ‘can’t verify’ outcomes operationally—what is the exception decision tree, who signs off, and how do you avoid inconsistent HR decisions across business units?
In employee screening operations, “can’t verify” outcomes are best handled through a defined exception pathway that distinguishes verification limits from adverse findings and routes hiring decisions to accountable business owners under shared rules. This avoids reviewers improvising outcomes and reduces inconsistent treatment across business units.
Operationally, organizations specify what constitutes reasonable verification effort for each check type, such as a set number of contact attempts or retries with a data source. Reviewers document those attempts and, if the target remains unresponsive or records remain inaccessible, they record an “unable to verify” outcome using standardized reason codes that indicate the underlying cause. Instead of closing such cases as fully clear, the workflow routes them to HR or a designated risk approver for decision, and this handoff and decision are logged with timestamps and approver identity.
Consistency across business units comes from a central policy, even if high-level, that maps “can’t verify” reasons to recommended hiring actions by role or risk tier. For less sensitive roles, a documented “can’t verify” for an older employer might be acceptable, whereas regulated or critical roles might require alternative evidence or lead to withdrawal. These rules are communicated in policy documents and job aids, and where possible reflected in decision-support prompts inside the workflow. To maintain alignment, central HR or Compliance periodically reviews how often “can’t verify” cases are accepted or declined by unit and feeds insights back into calibration. Clear, transparent communication to candidates about the nature of a “can’t verify” outcome and any next steps helps reduce disputes and protects candidate experience.
If a business leader insists we onboard someone despite open exceptions, how do you document the approval and risk acknowledgement?
C1893 Forced onboarding with open exceptions — In employee background verification, what operational workflow exists when a business leader forces an onboarding deadline despite open exceptions, and how do you document the exception, approver identity, and risk acknowledgement?
When a business leader insists on meeting an onboarding deadline despite open exceptions, employee background verification operations should channel that request through a formal risk-acceptance workflow. This ensures that the override is explicit, attributable to a named approver, and supported by a record of what was known at the time.
In practice, the verification team summarizes the pending checks and associated risks and marks the case with a specific status such as “onboarded with pending BGV” rather than full clearance. The workflow routes the case to an authorized approver, typically a senior HR or business owner, with Compliance informed or included according to policy. The approver records a decision to proceed, along with a reason and any conditions, such as limiting access to sensitive systems until checks close. This decision, and the identity and role of the approver, are captured in the case record with timestamps.
The same workflow also defines what happens if subsequent verification yields adverse findings. For example, policies may require immediate review by HR and Compliance, potential role reassignment, or employment action based on predefined thresholds. By consistently documenting overrides and linking them to later outcomes, organizations can monitor how often “hire under exception” decisions occur, whether they correlate with incidents, and whether policies or risk tiers need tightening. This approach protects the verification function from pressure to clear cases informally while giving business leaders a structured path to balance speed and risk.
If field work uses subcontractors, how do you stop them from improvising on exceptions, and what metrics prove they meet escalation SLAs?
C1894 Subcontractor control in exceptions — In employee BGV vendor operations, how do you keep subcontractors or field networks from creating uncontrolled exception handling practices, and what oversight metrics prove compliance with your escalation SLAs?
In employee BGV vendor operations, subcontractors and field networks are constrained from creating uncontrolled exception practices by being required to use centralized workflows, standardized exception codes, and prescribed escalation paths, and by being measured and governed against those standards. The aim is that an address or employment exception is handled the same way whether raised by an in-house reviewer or a field agent.
Subcontractors are onboarded onto defined processes and, where possible, onto the same or a dedicated connected interface that exposes only approved actions and exception reasons. They must record issues such as unreachable addresses, safety concerns, or missing documents by selecting standard codes, uploading evidence, and triggering escalation through the system or agreed channels rather than inventing their own categories or offline workarounds. Even when some activities occur offline, policies require that outcomes and evidence be captured back into the central case record, keeping the exception trail visible.
Oversight combines metrics and governance. Organizations track exception frequency, types, TAT adherence, and QA outcomes by subcontractor or field network, using identifiers or assignment records to attribute work. Outliers in exception rates, incomplete documentation, or repeated SLA misses prompt targeted audits, retraining, or, if needed, contractual consequences. Contracts and standard operating procedures explicitly reference required workflows, documentation norms, and escalation SLAs so that alignment is not only operational but also enforceable. This structured combination of process, tooling, measurement, and contractual governance reduces the risk of shadow exception practices in distributed networks.
How do you align HR’s time-to-hire goals with ops closure rate so exceptions don’t become a blame game after go-live?
C1897 Preventing KPI blame game — In employee BGV operations, how do you reconcile conflicting KPIs between HR (time-to-hire) and Operations (case closure rate) so exception handling does not become a political blame game after go-live?
In employee BGV operations, preventing exception handling from turning into a political fight between HR and Operations requires aligning their KPIs around shared, risk-aware goals and making delay ownership visible in the workflow. When both functions see how exceptions move and where time is actually spent, debates shift from blame to trade-off management.
Organizations start by agreeing that verification success is not just speed or just closure rate, but a combination of timely hiring and defensible checks. They then configure workflows and reporting so cases record time spent in key states, such as “pending at candidate,” “pending at HR,” and “under review,” and attribute those intervals to responsible owners. Even if tooling cannot track this perfectly, approximate measures via status changes and timestamps provide enough signal to see patterns.
Joint review forums, often involving HR, Operations, and Compliance, use these shared views when exceptions spike. They can see, for example, whether increased time-to-hire stems from deeper checks, slow HR responses to data-quality exceptions, or candidate delays. Decisions about adjusting exception rules, adding capacity, or tightening HR data validation are then based on agreed evidence rather than perception. Over time, organizations may introduce linked KPIs or targets, such as maintaining both a maximum average verification TAT and a minimum quality threshold, to reinforce that neither function can optimize its metric at the other’s expense.
If a key court/police source is down for days, what workflows keep hiring moving while clearly documenting pending checks?
C1898 Source outage pending-check workflow — In employee background verification (BGV) operations, if a major court-record or police-record data source becomes unavailable for days, what exception workflows keep hiring moving while preserving defensible documentation of ‘pending’ checks?
In employee BGV operations, when a major court-record or police-record data source is unavailable for an extended period, organizations rely on predefined exception workflows that explicitly mark affected checks as “pending due to external outage,” maintain clear documentation, and apply risk-tier-based decisions about whether hiring can proceed. This keeps hiring from stalling completely while preserving a defensible record that verification depth was temporarily constrained by factors outside the organization’s control.
Cases that require the impacted check are tagged with a dedicated status and reason code linked to the outage, rather than being shown as clear. Policies, often differentiated by role criticality and sectoral regulation, determine whether onboarding must wait for the check to complete or can proceed under conditions such as delayed high-privilege access or additional oversight. In regulated contexts where onboarding without completed checks is not allowed, the workflow simply holds such cases while clearly signaling the reason and expected delay to HR.
Throughout the outage, HR and relevant stakeholders see, via dashboards or status reports, which candidates are affected and how long checks have been pending. Once the data source resumes, backlogged checks are processed in a prioritized fashion, and any previously onboarded candidates have their records updated with final results. The audit trail for each affected case shows when the outage started, how the case was classified, what interim decisions were taken, and when normal verification resumed, which supports later regulatory or internal review.
Reviewer ergonomics, automation handoffs, and user experience controls
Addresses how reviewer ergonomics, explicit overrides with rationale, and safe automation handoffs reduce manual touches and preserve auditability. Covers multilingual notes, side-by-side evidence views, and consistent candidate communications to minimize friction.
What reviewer features do you have to cut down manual effort per BGV/IDV case (bulk actions, prefill, better evidence views)?
C1857 Reviewer ergonomics to cut touches — In digital identity verification (IDV) and employee BGV programs, what reviewer ergonomics features exist (keyboard shortcuts, bulk actions, smart prefill, side-by-side evidence view) to reduce manual touches per case?
Reviewer ergonomics in digital identity verification and employee BGV programs are supported by interface and workflow features that cut manual touches per case without sacrificing accuracy or auditability. These capabilities directly influence reviewer productivity, escalation ratios, and case closure rates.
Keyboard shortcuts and streamlined action menus reduce the number of clicks needed for common tasks such as approving checks, requesting additional information, or escalating exceptions. Bulk actions allow reviewers to process groups of similar cases where policy permits, while smart prefill uses existing data to auto-populate fields that would otherwise require repetitive entry.
Side-by-side evidence views present candidate declarations alongside documents, registry responses, or risk intelligence outputs so reviewers can compare information without switching contexts. Filters and configurable queues let reviewers concentrate on specific check types or severities, lowering cognitive load during high-volume periods.
These ergonomics features are paired with audit trails that record user actions and decisions to prevent over-automation from eroding control. Training and accessible design help ensure that reviewers can use shortcuts, bulk tools, and evidence views effectively, so operational benefits translate into measurable gains in throughput and consistency.
How do you stop borderline cases from bouncing between automation and manual review, and what controls the handoff?
C1860 Control automation-to-manual handoffs — In employee BGV and IDV verification operations, how do you prevent ‘ping-pong’ between automated decisions and manual review for borderline cases, and what thresholds or rules control that handoff?
Employee BGV and IDV operations prevent “ping-pong” between automated decisions and manual review for borderline cases by setting clear thresholds for automation, defining when human review is authoritative, and constraining how re-processing occurs when new information appears. The aim is to keep decision flows efficient and explainable rather than cycling cases between engines and reviewers.
Organizations establish risk or confidence bands for automated scoring and matching. High-confidence outcomes may follow straight-through processing, while intermediate bands are routed once to manual review. Policies clarify that for a given screening cycle, a human decision on a borderline case becomes the reference outcome unless additional evidence or risk signals are introduced.
Workflows support this by marking cases that have undergone manual review and limiting automatic re-evaluation to defined triggers, such as new documents, updated identity information, or scheduled re-screening events. Exception queues aggregate borderline cases, allowing experienced reviewers to handle them consistently instead of repeatedly pushing them back to automation.
Monitoring tracks the proportions of straight-through, manual, and exception-path cases and examines where automation disagrees with human judgement. Thresholds and routing rules are then tuned so automation is applied where it is reliable, and manual intervention is reserved for genuinely ambiguous or high-impact situations, maintaining decision paths that remain traceable for audits and disputes.
What exception codes do you support, and can we configure them to match our HR risk tiers and policies?
C1861 Exception taxonomy and configurability — In background verification case operations, what are the standard exception categories and codes your platform uses, and can an enterprise configure them to match internal HR risk tiers and policies?
Exception categories in background verification operations are typically organization-defined rather than governed by a single industry standard, and mature enterprises usually align these categories with internal HR risk tiers and policies. Most programs group exceptions into patterns such as data quality issues, source or registry unavailability, candidate non-cooperation, and explicit policy deviations.
In practice, organizations treat exception codes as part of their broader background verification policy and risk architecture. Operations teams define clear labels for recurring issues, for example incomplete candidate data, unreachable employers, or address verification failures, and then map each label to actions such as candidate follow-up, re-attempt windows, or escalation to HR or Compliance. This mapping supports queue management, SLA tracking, and consistent reporting across HR, Risk, and Procurement stakeholders.
There is significant variation in how much configuration different platforms allow, so enterprises that want close alignment to internal risk tiers should make exception taxonomy configurability a requirement in evaluation and RFP stages. A common failure mode is lifting a vendor’s default codes without redesign, which leads to noisy dashboards and weak audit narratives. More mature programs periodically rationalize exception categories based on observed escalation ratios and case closure patterns, and they use the same categories consistently in dashboards, audit evidence packs, and commercial SLAs to maintain transparency and defensibility.
How do you handle poor or missing inputs (blurry IDs, incomplete addresses) without overloading reviewers or losing candidates?
C1862 Handling low-quality candidate inputs — In employee BGV operations, how does the case workflow handle missing or low-quality inputs (blurry IDs, incomplete addresses, inconsistent names) without creating excessive reviewer workload or candidate drop-offs?
Employee background verification workflows manage missing or low-quality inputs by combining upfront data validation, structured exception categories, and selective human review to protect both reviewer capacity and candidate experience. The operational objective is to prevent obviously unusable data from entering downstream checks while reserving manual effort for genuinely ambiguous or higher-risk cases.
Many organizations start by designing digital forms with mandatory fields, format validations, and guided address capture to reduce incomplete submissions. Where digital identity proofing is in scope, technologies such as document validation, OCR/NLP, and liveness or face matching can flag unreadable IDs, mismatched names, or inconsistent attributes, which are then tagged in the case as specific data-quality exceptions. Case management workflows typically use these tags to trigger automated candidate notifications, request re-upload of documents, or set defined re-attempt windows before any escalation to reviewers.
Risk-tiered policies play a central role in avoiding excessive escalation ratios and drop-offs. For roles or geographies with stricter regulatory expectations, organizations often require complete and high-quality inputs before verification can proceed. For less critical roles, policies may permit limited progression with clear follow-up tasks, provided consent, purpose limitation, and auditability are maintained. A common failure mode is routing every data issue into manual queues without differentiation, which drives up turnaround time and reviewer workload. More mature programs monitor escalation ratios and case closure rates, then iteratively tune validation rules, exception paths, and communication templates so that only materially impactful anomalies reach human reviewers.
How do you manage field address verification end-to-end (geo proof, retries, closure), and what happens when visits fail?
C1865 Field address verification exception flow — In background screening operations, how are field address verification tasks created, tracked, and closed (geo-presence proof, timestamping, reattempt rules), and how are exceptions escalated if field visits fail?
In background screening operations, field address verification tasks are translated into structured assignments that specify what needs to be checked, where, by whom, and within which SLA, with traceable evidence requirements. The operational objective is to turn candidate-provided address details into verifiable field actions with consistent outcomes and defined exception paths.
Task creation generally standardizes the address format and routes it to a field network based on geography, coverage, and capacity. Many programs expect field agents to capture dated photographs, visit notes, and where feasible geo-location indicators that demonstrate proof-of-presence and time of visit. These artifacts become part of the case evidence bundle and are checked against predefined criteria before a task is marked complete, whether the outcome is confirmation, address not traceable, or other defined result labels. The exact naming of these outcomes varies by organization but is usually codified in operating procedures.
When field visits cannot be completed, exception rules govern re-attempts and escalation. Common patterns include multiple visit attempts at different times or days and clear cut-offs after which the check is closed as not verified in line with policy. Cases involving persistent failures, patterns suggesting potential fraud, or discrepancies between field observations and documentation are typically escalated to a central review or risk function. Because field operations can be intrusive and data-intensive, privacy and purpose limitation obligations apply to any collection of images or location data, and organizations factor these constraints into the design of their instructions, evidence requirements, and retention policies.
How can reviewers override automated flags, and how do you capture the reasoning for audit purposes?
C1867 Reviewer overrides with rationale logging — In employee screening workflows, what is the reviewer override process for automated flags (false positives, fuzzy-match collisions), and how is the rationale captured for audit and internal governance?
In employee screening workflows, reviewer override of automated or rule-based flags is a key human-in-the-loop control that protects against false positives and fuzzy-match collisions, especially in court, sanctions, or adverse media checks. The process is designed so that automation proposes alerts, but humans retain responsibility for final judgments in ambiguous or high-impact cases.
Operationally, systems surface alerts together with supporting evidence, such as matched names, identifiers, and source snippets. Reviewers then decide whether the alert represents a valid match or an error and record an explicit decision in the case. More mature operations use structured override options, for example predefined reason categories such as “different person,” “outdated information,” or “context not relevant,” combined with a free-text field for narrative explanation. User identity, timestamp, and any changes to case status or risk level are stored as part of the audit trail or chain-of-custody.
These override records serve multiple purposes. They support downstream dispute resolution and internal investigations by showing why a particular alert was upheld or dismissed. They also provide feedback signals to adjust matching thresholds, tuning rules, or data sources when certain alert types attract high override rates. A common failure mode is handling overrides via informal channels such as email, which fragments the evidence trail and weakens explainability during audits or candidate challenges. More advanced programs therefore treat overrides as formal workflow events with controlled permissions and consistent documentation.
If the platform has an outage or webhook delays, how do you handle stuck cases and notify HR/candidates to reduce churn?
C1899 Outage handling for stuck cases — In employee BGV and IDV operations, when the verification platform has an outage or webhook delays, what is the exception-handling process for stuck cases and how are HR and candidates notified to prevent churn?
In employee BGV and IDV operations, when the verification platform suffers an outage or webhook delays, exception handling centers on isolating affected cases, preventing silent stalling, and proactively informing HR and candidates so delays are understood and traceable. Systems and processes treat such events as a specific exception type with recognizable codes and documented handling steps.
Operations teams detect issues through monitoring of latency, error rates, or, in less mature setups, through rapid escalation of user complaints. Impacted cases are flagged as “system-impacted” or similar, and automated retries are scheduled for failed calls once services stabilize. Where architecture allows, organizations may accept candidate data but queue verification calls, or temporarily pause new initiations to avoid inflating backlogs. The outage window and subsequent actions are recorded in case histories so future reviewers can see why TAT breached normal targets.
Clear communication reduces churn and mistrust. HR receives timely updates on incident scope, affected check types, and expected recovery times, enabling them to plan onboarding timelines and respond to hiring managers. Candidates see transparent status messages explaining that verification is delayed due to technical issues, not because of anything they did, along with revised expectations. For longer or repeated disruptions, Compliance and Risk functions assess whether regulatory incident reporting or client notifications are required. Post-incident reviews tie operational impact back to improvements in resilience, such as more robust webhook handling, better failover paths, or refined fallback processes.
What’s a practical checklist to set escalation SLAs by check type (employment/education/CRC/AV) before we run the pilot?
C1900 Checklist for escalation SLA setup — In employee background screening operations, what is the practical checklist a verification program manager should use to set escalation SLAs by check type (employment, education, CRC, address verification) before the pilot starts?
In employee background screening operations, a verification program manager should set escalation SLAs by check type using a checklist that clarifies when a case becomes an escalation, who owns it, and what fallback options are acceptable for employment, education, criminal record checks (CRC), and address verification. This structure turns escalation from an ad-hoc reaction into a predictable workflow before the pilot starts.
A practical checklist includes, for each check type: the maximum number of verification attempts or contact cycles in normal processing; the time interval without progress after which a case is flagged for escalation; the designated escalation owner (for example, a senior reviewer, a specialist team, or client HR); and the allowed next steps if the check remains unresolved, such as requesting alternative documents or marking “unable to verify” under defined conditions. For CRC and address checks, the manager documents whether additional steps like deeper database searches or field visits are in scope, recognizing that not all programs will support these options.
The manager also defines how escalations will be tracked and reviewed. This includes agreeing on fields or tags that mark an escalation, the expected resolution time once escalated, and the reporting view that will show escalation rate and impact on overall TAT by check type and, where relevant, by role risk tier or jurisdiction. These parameters are documented and validated with HR, Compliance, and vendors before the pilot so that early results can be interpreted against known expectations and thresholds can be tuned without confusion.
How do you stop reviewers from quietly closing escalations just to hit targets, and how do you audit for it?
C1901 Prevent silent escalation closures — In employee BGV operations, what workflow controls ensure that escalations are not silently closed by reviewers (for example, to meet case closure targets), and what audits detect this behavior?
Employee BGV operations prevent escalations from being silently closed by combining permission controls on status changes, mandatory justification when closing exceptions, and independent review of closure decisions. Audit analytics on case histories then flag abnormal closure patterns that may be driven by case-closure targets rather than evidence.
Most organizations start by restricting who can move a case from “escalated” to “closed.” Role-based permissions ensure only designated reviewers or supervisors can take that step. The workflow enforces selection of a standardized closure reason for each escalation and requires a short free-text note before status change. Even in basic tools, operations teams can record who changed the status and the timestamp in a shared log or spreadsheet to create a minimal chain-of-custody.
Quality assurance and Compliance teams then review a sample of closed escalations, with extra focus on high-risk checks such as criminal record checks, court or police record screening, leadership due diligence, and adverse media alerts. Reviewers compare the closure reason and notes against available evidence, including employment or education confirmations and any court record hits.
Audit analytics commonly look at the distribution of escalation closures by reviewer, by check type, and by age of the escalation. Warning signals include very fast closures of high-risk escalations, reviewers whose escalations are almost never upheld, and sudden drops in overall escalation ratio while underlying discrepancy rates stay flat. Where case closure TAT is a KPI, organizations balance it with quality indicators such as re-open rates or secondary review findings so reviewers are not pushed to close escalations prematurely.
When verification is inconclusive but we need to onboard, who owns the decision across HR/Compliance/IT?
C1902 Ownership for inconclusive verifications — In employee screening operations across HR, Compliance, and IT, how is accountability defined for exception outcomes—who owns the decision when verification is inconclusive but onboarding must proceed?
In employee screening operations, accountability for inconclusive verification outcomes is defined by a written ownership matrix that separates who assesses verification evidence from who owns the hiring or access decision. Verification teams or vendors are accountable for accurate, well-documented findings, while HR, Compliance, and the hiring manager jointly own the risk decision when onboarding must proceed despite incomplete assurance.
Organizations that operate defensibly record in their SOPs which roles can approve exceptions for each risk tier. For operational or low-risk roles, HR may have delegated authority to proceed with conditions, such as time-bound re-verification or restricted access. For financially sensitive, regulated, or leadership roles, exception approval usually requires sign-off from Compliance or the Chief Risk Officer, with the business line head explicitly recorded as a co-approver. IT or security is involved where the role grants access to critical systems or sensitive data, aligning with zero-trust onboarding principles.
The decision workflow captures the verification summary, the nature of the inconclusiveness, the documented risk assessment, the final decision (proceed, defer, or reject), and any conditions. The system or case record also stores the identities and timestamps of all approvers. This chain-of-custody clarifies who accepted the residual risk and helps resolve disputes between the employer and any external BGV vendor, since the vendor’s role is limited to evidence and classification under the agreed KYR policy, not the employment decision itself.
What SOPs handle repeated candidate resubmissions so we don’t get stuck in loops or burn out reviewers?
C1903 SOP for repeated resubmissions — In employee background verification operations, what operator-level SOPs exist for handling repeated candidate resubmissions (multiple ID uploads, multiple address proofs) to avoid infinite loops and reviewer burnout?
Employee background verification operations handle repeated candidate resubmissions through SOPs that define retry limits per check type, provide clear document guidance after each failed attempt, and route persistent failures to an exception decision rather than allowing open-ended loops. These practices protect reviewer capacity and convert repeated uploads into structured, auditable events.
Most organizations first segment checks by nature of evidence. Identity and address checks that rely on candidate uploads often have explicit retry thresholds and cut-off timelines, while employment or education checks that depend on issuers follow different patterns. SOPs specify, for each check, how many resubmissions are normally entertained, what constitutes a materially different document, and when the case moves from “pending documents” to an exception queue for HR or Compliance review.
After each rejection, reviewers use standardized reason codes and simple explanations to tell the candidate what went wrong, along with examples of acceptable alternatives. Where digital portals exist, these explanations appear in the candidate journey. In more manual environments, teams rely on email templates or SMS messages to keep language consistent and reduce back-and-forth.
Operations leaders track metrics such as average attempts per check, proportion of cases hitting retry thresholds, and reviewer handling time for high-retry cases. A spike in resubmissions can signal unclear instructions, mobile-flow friction, or potential fraud. Clear retry rules, time-boxed follow-ups, and defined escalation paths help avoid infinite loops and reduce reviewer burnout without depriving candidates of reasonable chances to comply.
How do you run risk-tiered exception handling so high-risk roles get deeper review and low-risk roles close faster?
C1904 Risk-tiered exception workflow design — In employee BGV operations, how do you operationalize risk-tiered exception handling so that high-risk roles get deeper review while low-risk roles get faster closure with fewer manual steps?
Risk-tiered exception handling in employee BGV operations is implemented by mapping each role to a defined risk tier and linking that tier to specific exception review depth, approval paths, and manual intervention requirements. High-risk roles receive deeper exception scrutiny and senior sign-offs, while low-risk roles are allowed faster closure for clearly bounded issues.
Organizations first classify roles using criteria such as access to money or financial systems, regulatory obligations, data sensitivity, and seniority. For each tier, they define which checks are mandatory, which discrepancies are absolute blockers across all tiers, and where limited flexibility is allowed. For example, a relevant criminal record or sanctions hit would normally block onboarding regardless of tier, whereas a minor address mismatch might be handled differently for a junior role than for a leadership role.
These rules can be encoded in workflow tools where available, or in structured SOPs and checklists when operations still rely on email or spreadsheets. When an exception is raised, reviewers refer to the tier-based matrix to determine whether automated closure is allowed, whether a single HR approver is sufficient, or whether a joint decision from Compliance and the business owner is mandatory. Documentation of the tier, the exception type, the risk rationale, and approver identities is stored with the case to support audits.
Operations leaders monitor TAT, escalation ratios, and manual touches per case by risk tier. If high-risk exceptions appear to close as quickly as low-risk ones, or if stakeholders seek informal bypasses for senior hires, governance teams revisit the tier definitions and communication. Explaining to HR and business managers why critical roles legitimately face more friction helps sustain the integrity of risk-tiered handling while preserving speed for low-risk hiring.
For cross-border hires, how do you handle exceptions when overseas employment verification is delayed by data access constraints?
C1906 Cross-border employment exception handling — In employee BGV operations, how do you handle cross-border hiring exceptions when a candidate’s prior employment is in another country and data access constraints delay verification?
Employee BGV operations handle cross-border hiring exceptions by explicitly flagging overseas checks, defining extended but finite waiting periods, exploring legally appropriate alternative evidence, and routing unresolved cases through a documented exception decision rather than assuming normal assurance. The goal is to acknowledge jurisdictional constraints while keeping risk, compliance, and candidate experience in balance.
Verification teams tag checks that depend on foreign employers, courts, or registries with the relevant country and the reason for delay. SOPs define how long teams will wait for responses from that jurisdiction before escalating the case. During this period, candidates receive clear communication about expected TAT and the specific dependency, which reduces confusion and perceptions of unfair treatment.
Where local law and policy permit, organizations may ask candidates for secondary evidence of overseas employment, such as employer letters or other non-sensitive records, while clearly noting in the final assessment that these sources do not replace issuer-confirmed BGV. In some jurisdictions, legal or cultural norms limit what can be requested, so Compliance validates acceptable alternatives in advance.
Once the waiting threshold is crossed, exception workflows specify who can approve onboarding with partial verification, usually by role risk tier. High-risk or regulated roles may be deferred, restricted in system access, or subject to later re-screening when better data becomes available. All attempts to verify, the legal or practical constraints encountered, evidence obtained, and the final decision are documented for audit and for DPDP- or GDPR-style cross-border data governance reviews.
How do you ensure exception messages to candidates are consistent and legally safe when requesting more evidence?
C1907 Candidate messaging governance in exceptions — In employee BGV workflows, what operational controls exist to ensure exception communications to candidates are consistent, non-threatening, and do not create legal exposure while requesting additional evidence?
Employee BGV workflows keep exception communications to candidates consistent and non-threatening by using pre-defined messages, aligned with legal guidance, that request information in neutral, process-focused language. These messages explain what extra evidence is needed, by when, and for which check, without suggesting misconduct or making legal conclusions.
Organizations usually develop short, plain-language templates for common exception scenarios such as unclear ID images, incomplete address proofs, or missing employment documents. Each template specifies the check name, the exact document formats that are acceptable, and simple steps to upload or share them. References to consent, purpose, and data handling are kept concise, often by linking to or briefly mentioning the consent notice the candidate already accepted, rather than repeating full legal text in every message.
Because candidates interact over multiple channels, these templates are adapted for email, SMS, in-app notifications, and call scripts. Operations staff and call center agents are trained to follow the approved phrases closely, particularly for sensitive topics like potential criminal record matches or adverse media findings. All outbound communications, including channel and content, are logged against the case for audit and dispute resolution.
Compliance or the Data Protection Officer periodically reviews template wording to ensure it is accurate, proportionate, and aligned with DPDP-style privacy and fairness expectations. Where local legal expertise is limited, organizations can still standardize tone and structure internally and update content when regulations or internal policies change, reducing legal exposure from improvised, inconsistent messaging.
If Procurement wants fewer paid checks but ops expects more exceptions, what data shows the real cost of exceptions and rework?
C1908 Exception economics for procurement tradeoffs — In employee background verification operations, when Procurement pushes for fewer paid checks but Operations fears higher exceptions, what workflow data proves the cost impact of exceptions and rework?
When Procurement seeks to reduce paid checks and Operations anticipates more exceptions, employee BGV teams use workflow data that quantifies how check coverage affects exception frequency, manual effort, and turnaround time. This shifts the discussion from per-check cost to total cost of verification and hiring risk.
Operations teams start by measuring exception rates by check type and role category, along with the average number of manual touches and additional days required to resolve those exceptions. Where historical variation exists, such as pilots with lighter bundles or different risk tiers, they compare these cohorts to estimate how often reduced coverage leads to extra clarifications, re-opened cases, or longer TAT.
Even when only one bundle has historically been used, teams can model scenarios by simulating what would have happened if a given check were absent, for example by flagging cases where that check alone detected a discrepancy. This helps show how often a particular check prevented clean-but-risky onboarding or avoided subsequent disputes.
Data is always interpreted within regulatory constraints, since some checks in sectors like BFSI or gig platforms are mandated and not optional. Presenting exception ratios, manual touches per case, and TAT distributions alongside per-check fees allows Procurement, HR, and Compliance to evaluate trade-offs transparently. This workflow evidence demonstrates that aggressive cost-cutting can increase operational workload and hiring delays, which may outweigh savings on reduced check volume.
For predictable peaks (campus drives, festive gig onboarding), what runbooks and surge staffing plans prevent exception backlogs?
C1911 Peak-period runbooks for exceptions — In employee BGV operations, what runbooks and staffing surge plans exist for predictable peak periods (campus hiring, festive-season gig onboarding) to keep exception backlogs from growing uncontrollably?
Employee BGV operations manage predictable peak periods such as campus hiring or festive-season gig onboarding by maintaining runbooks and surge plans that explicitly address exception workloads. These plans combine staffing strategies, prioritization rules, and exception-specific monitoring so that backlogs stay within acceptable bounds even when intake spikes.
Runbooks describe expected peak windows, typical case profiles, and target SLAs for verification, including how quickly exceptions must be triaged. Where historical data is limited, teams use conservative estimates and update assumptions after each cycle. Surge plans outline how many additional reviewers or QA staff can be mobilized, how cross-trained resources from adjacent teams will support exception queues, and which managers own decisions on overtime or temporary hires.
To avoid overwhelming staff, organizations simplify or automate steps ahead of known peaks, especially in high-volume checks like address or identity verification. Clear SOPs for common exception patterns reduce decision time. During peaks, dedicated reviewers often focus only on exceptions while standard cases flow through more automated paths appropriate to their risk tier.
Operations teams monitor queue aging distribution for exceptions, escalation ratios, and backlog size, with predefined thresholds that trigger temporary “war-room” coordination, reprioritization of work, or broader stakeholder involvement. Any temporary adjustments to risk-tiered handling, such as deferring non-critical re-screens, are explicitly documented, time-bound, and reviewed with Compliance to ensure that peak management does not erode overall governance or regulatory defensibility.
How do you coordinate exceptions between your ops team and our HR ops so cases don’t stall waiting on each other?
C1913 Buyer-vendor coordination for exceptions — In employee background verification operations, how do you coordinate exception handling between the vendor’s verification ops team and the buyer’s HR ops team so cases don’t stall due to ‘waiting on each other’?
Employee background verification programs coordinate exception handling between vendors and buyer HR teams by defining clear ownership for each exception type, exposing “who is waiting on whom” in shared case statuses, and monitoring joint SLAs on queue aging. These controls reduce the likelihood that cases stall because each side assumes the other is progressing them.
At a minimum, contracts or SOPs describe which party is responsible for actions such as contacting candidates, re-chasing employers, or reviewing potential criminal or court record hits. Case statuses distinguish between “pending with candidate,” “pending with vendor,” and “pending with client HR,” so both teams can see when the next move is theirs. Where full system integration is not available, vendors provide regular case extracts or dashboards that HR teams use as the system of reference for pending actions.
Exception-related SLAs specify maximum time limits for each party to act on a pending item, for example how long HR can keep a case in review after the vendor raises an exception, or how quickly the vendor must respond once HR provides new information. Reports on queue aging and escalation ratios are shared, and chronic stalls in any status category trigger follow-up discussions.
Periodic operations reviews, even if brief during busy periods, focus explicitly on exceptions that exceed thresholds and on any ambiguous scenarios where responsibilities overlap. Over time, both sides refine playbooks and standard communications for recurring exception patterns, which further reduces confusion and increases the predictability of hand-offs.
For leadership or VIP hires, what escalation path exists, and how do you prevent it from turning into a governance bypass?
C1914 VIP exception handling without bypass — In employee screening operations, what escalation paths exist for ‘VIP’ or leadership hiring exceptions, and how do you prevent those paths from becoming informal bypasses that weaken governance?
In employee screening operations, escalation paths for ‘VIP’ or leadership hiring exceptions route cases to designated senior decision-makers while keeping the standard verification baseline intact. Governance relies on documented escalation rules, multi-party sign-off for deviations, and audits that check whether VIP handling followed policy rather than informal shortcuts.
Leadership roles are usually assigned to the highest risk tiers, with broader checks such as court and criminal record screening, adverse media review, and leadership due diligence. When exceptions arise, SOPs specify that the case moves beyond routine HR review to a defined set of approvers, which may include the CHRO, Compliance or Risk head, and the relevant business leader. In smaller organizations this may be a small group rather than a formal committee, but the membership and responsibilities are still documented.
Policies state that VIP status does not reduce mandatory checks and that any waiver or compression of checks must be justified in writing, linked to the specific risk assessment, and countersigned by more than one senior stakeholder. The case record includes the exception details, the evidence reviewed, the final decision, and any conditions, such as probation with re-verification or restricted initial access.
Compliance or internal audit periodically reviews leadership hiring cases to look for patterns of unapproved bypassing or unusually fast closures relative to policy. Even if incident data is sparse, these reviews help ensure that escalation paths are used for deeper deliberation, not to weaken controls. Clear communication to sponsors and hiring managers that VIP escalations add scrutiny rather than shortcuts is essential to maintaining robust governance around senior appointments.
What signals tell us exception handling is slipping (queue aging, escalation ratio, dispute time), and what thresholds trigger a war-room?
C1915 Operational health indicators for exceptions — In employee BGV operations, what practical indicators show that exception handling is under control (queue aging distribution, escalation ratio, dispute cycle time), and what thresholds typically trigger an operational war-room?
In employee BGV operations, exception handling appears under control when exception queues age within agreed SLA windows, escalation ratios stay roughly stable for each segment, and dispute or re-open cycles do not materially distort overall TAT or reviewer workload. When these indicators move sharply or persistently away from baselines, organizations often initiate an operational war-room to restore stability.
Core metrics include queue aging distribution for exception cases, such as the percentage that exceed the organization’s normal resolution window for a given role tier or check type. Escalation ratio, defined as exceptions or escalations relative to total cases, is tracked separately for segments like white-collar, blue-collar, and gig hiring, since baseline levels differ. Dispute or re-open cycle time is measured from the moment an exception is raised to final closure, indicating how long problematic cases remain active.
Additional signals include the share of reviewer time spent on exceptions versus standard cases and the impact of exceptions on end-to-end TAT. If exception backlogs grow so that a rising proportion of cases breach SLAs, or if escalation ratios climb significantly above typical ranges for several reporting periods, leaders treat this as a trigger for coordinated intervention.
War-room responses bring together HR, BGV operations, the external vendor where applicable, and sometimes Compliance. They review exception metrics by check type, role tier, and source system to identify root causes such as data quality issues, process gaps, or staffing shortages. Targeted actions then adjust staffing, clarify SOPs, or refine risk-tiered rules until exception indicators return to expected ranges.
Can reviewer notes and exception reasons be standardized and multilingual so audits and handoffs stay clear?
C1916 Standardized notes and multilingual support — In employee BGV operations, how does your workflow support multilingual reviewer notes and standardized exception reasons so that audits and cross-team handoffs remain understandable?
Employee BGV operations keep exception histories understandable across teams and audits by combining standardized exception reason codes with carefully governed free-text notes that can be entered in multiple languages. Structured codes provide consistent categorization, while notes capture local nuance without undermining cross-team readability.
Organizations define a controlled list of exception reason codes in a reference language, often English, for scenarios such as “insufficient address proof,” “issuer non-response,” or “potential court record match.” Reviewers select one or more of these codes whenever they raise or close an exception. Because reports and dashboards rely on codes rather than free-text, analytics and audit summaries remain comparable across regions and languages.
Alongside codes, systems or SOPs allow brief notes in local languages where necessary, especially for field-based address verification or region-specific issues. To support audits and cross-team handoffs, teams may either include a short summary in the reference language or rely on templated phrases for common patterns, reducing the burden on reviewers with limited language skills.
Governance guidelines remind reviewers to keep notes factual, concise, and limited to information relevant to the verification purpose, which supports privacy and fairness expectations under DPDP-style regimes. Periodic sampling of notes by supervisors or Compliance checks for inappropriate content or unnecessary sensitive details. This approach lets frontline teams work comfortably in local languages while preserving a standardized, regulator-ready view of exception reasons and case histories.
Do you have peer references specifically about exception handling—escalation SLAs, dispute management, and reviewer productivity?
C1917 Peer proof on exception operations — In employee BGV operations, what evidence shows your workflow is a ‘safe standard’ in the market for exception handling (peer references specifically on escalation SLAs, dispute management, and reviewer productivity)?
Employee BGV workflows are seen as a ‘safe standard’ for exception handling when organizations can point to consistent SLA performance on escalations, QA and audit outcomes that validate decisions, and independent endorsements from comparable peers. Together, these elements suggest that exception processes are predictable, documented, and aligned with prevailing regulatory expectations.
Operational evidence includes metrics on how quickly exceptions are acknowledged and resolved relative to published SLAs, how often exception decisions are overturned in internal QA, and how reviewer productivity holds up without spikes in error rates. Stable escalation ratios and manageable dispute cycle times across hiring cycles indicate that the process is working under real-world load rather than only in pilot conditions.
Internal validation from Compliance and audit functions is critical. Positive findings from audits that specifically review exception samples, chains-of-custody, and adherence to DPDP-style privacy and consent norms strengthen the claim that the workflow is defensible. Clear documentation of policies and decision rationales further supports this view.
For organizations working with external BGV vendors, peer references from CHROs, Compliance Heads, or IT leaders in similar sectors add a market benchmark. These references often describe how exception workflows performed during regulatory reviews, how disputes were handled, and what governance mechanisms are in place. While absence of enforcement action is not proof of best practice, a combination of strong internal reviews and credible third-party experiences gives stakeholders confidence that they are operating within a widely accepted and defensible standard.
Compliance, privacy, auditability, and risk management in BGV/IDV
Centers on consent management, purpose limitation, data retention, cross-border data constraints, and taxonomy of exceptions for regulator-ready trails. Emphasizes audit trails, escalation governance, and risk controls to defend verification decisions.
What’s your full candidate dispute flow in India (intake → evidence → reassessment → resolution) and how is it logged?
C1859 Candidate dispute resolution workflow — In India-first employee BGV operations, what is the end-to-end dispute workflow for candidates/employees (intake, evidence submission, reviewer reassignment, resolution SLA, and audit trail of changes)?
In India-first employee background verification operations, candidate and employee disputes are handled through a structured workflow covering intake, evidence submission, review, resolution SLAs, and an audit trail of changes. This process aims to address challenges to verification findings in a way that is transparent, fair, and defensible under emerging privacy and employment norms.
Disputes are typically raised through designated channels such as portals, email addresses, or support tickets where candidates can identify the specific check or finding they contest. The system logs the dispute, associates it with the original verification case, and notifies verification operations or Compliance teams so that the challenged elements are re-examined.
Candidates are invited to provide supporting evidence or clarifications, for example updated documents or explanations of employment or address histories. A reviewer is then assigned to reassess the contested items, consult relevant data sources, and document the rationale for upholding, modifying, or reversing the earlier outcome. Resolution SLAs define acknowledgement and closure timelines consistent with client policies and regulatory expectations.
Every dispute-related action, evidence submission, and change to case status or conclusions is recorded in an audit trail tied to the original case. Outcomes are communicated to the candidate and to the employer’s HR and Compliance stakeholders. Where necessary, data corrections made during dispute resolution feed back into retention and deletion practices so stored records reflect the final, agreed verification state.
If a candidate withdraws consent mid-verification, how do you stop checks and handle already-collected evidence?
C1866 Consent withdrawal during exceptions — In employee BGV operations under DPDP-style consent requirements, how does the exception workflow handle consent withdrawal mid-case, and what happens to in-flight checks and retained evidence?
Under DPDP-style consent requirements, employee background verification operations must treat mid-case consent withdrawal as a formal governance event that affects both ongoing checks and the handling of already collected evidence. The baseline expectation is that further processing for the original verification purpose should stop, subject to any clearly defined legal or contractual obligations that justify limited continued retention.
Operationally, when withdrawal is recorded, the background verification case should be marked accordingly, and no new data collection or fresh queries to employers, education boards, courts, or registries should be initiated under that consent. In more mature setups, consent status is integrated into workflow and API layers so that automated checks are halted. In lower-maturity environments, designated teams may need to manually stop in-flight activities and inform any field or vendor partners. Data and results already obtained are then handled according to the organization’s documented retention and deletion policy, which may allow restricted retention for purposes such as audit trails, dispute handling, or legal defense where lawful.
Because withdrawal can directly impact the ability to complete verification, many organizations state in their consent notices and privacy policies that ongoing consent is a condition for proceeding with background checks and, by extension, with hiring or onboarding. A common failure mode is capturing withdrawal logs but not wiring them into day-to-day operations, which can result in checks continuing after consent has been revoked. More mature programs maintain consent ledgers, map consent scope to specific verification purposes, and implement minimization and deletion routines aligned with retention schedules and candidate rights.
For high-volume gig onboarding, how do you triage exceptions to keep latency low without dropping assurance?
C1871 Gig onboarding exception triage — In high-volume gig-worker onboarding using IDV and BGV checks, how does the workflow triage exceptions to keep onboarding latency low while still meeting minimum assurance thresholds?
In high-volume gig-worker onboarding, background and identity verification workflows triage exceptions by applying risk-tiered checks and routing only higher-risk or ambiguous cases into slower manual review, so that most candidates complete quickly while minimum assurance thresholds for trust and safety are maintained. This approach is a response to materially high misconduct and discrepancy rates observed in gig workforces, including delivery theft, false representation, and address or court-record discrepancies.
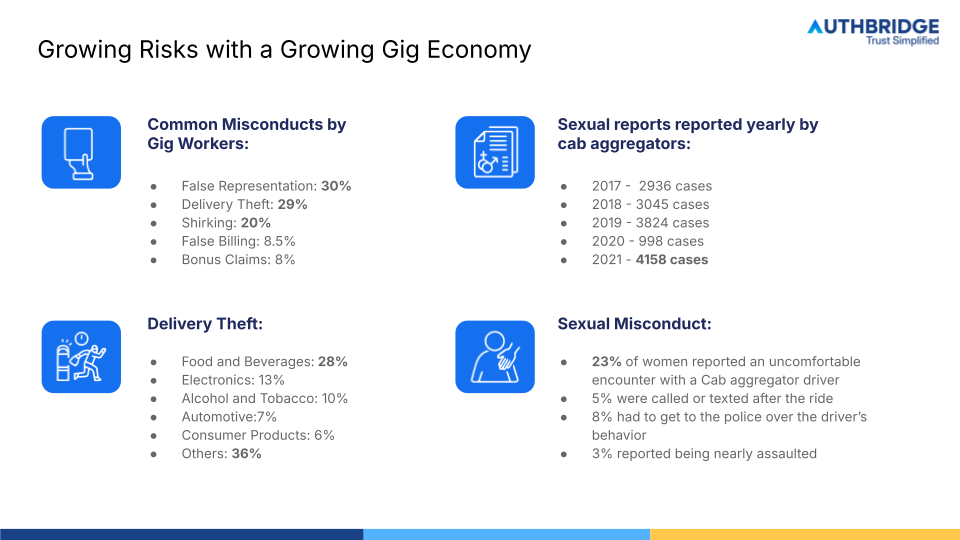
Operationally, platforms often segment workers by role risk, geography, or historical incident patterns and assign verification bundles accordingly. Automated checks such as document and identity validation, basic address verification, and court or criminal database screening are run as quickly as possible, with only exceptions or risk signals flowing into manual queues. Typical exceptions include identity mismatches, material address discrepancies, and relevant legal or misconduct indicators. These are triaged by severity and type; for example, minor address inconsistencies may prompt additional digital verification, whereas serious court or misconduct flags are escalated to specialized review and can block onboarding entirely for certain roles.
To keep latency low, organizations define service levels for exception queues, closely monitor discrepancy rates and queue aging, and periodically adjust routing thresholds in line with their risk appetite and regulatory context. In some lower-risk use cases, they may choose to allow tightly controlled conditional activation with enhanced monitoring until deeper checks complete, whereas in safety-critical or regulated roles they typically require full clearance before granting access. A common failure mode is treating all anomalies as equally urgent, which overwhelms reviewers and increases onboarding delays. More mature programs explicitly differentiate exception types and tie triage rules to documented trust and safety policies.
How do you handle identity resolution conflicts (duplicates/alias collisions) and prevent wrongful adverse outcomes?
C1876 Identity resolution conflicts handling — In employee background screening, what is the process for handling identity resolution conflicts (two candidates matching one identity record, alias collisions), and how does the workflow prevent wrongful adverse decisions?
In employee background screening, identity resolution conflicts such as two candidates apparently matching the same external identity record or alias collisions in legal and sanctions databases are managed through cautious matching practices, structured human review, and explicit controls against wrongful adverse decisions. The guiding principle is that ambiguous identity links should trigger further investigation rather than automatic negative outcomes.
Where tools support it, smart or fuzzy matching is used to surface possible matches based on combinations of attributes such as name, date of birth, and address. When these processes produce collisions—for example, multiple candidates aligning with the same court record entry, or one candidate aligning with several similar records—the workflow routes such cases into manual review. Reviewers then assess additional identifiers, supporting documents, and contextual information, and either confirm the association or record it as a false positive. In less automated environments, similar decisions are made using manual searches and comparisons but should still follow documented procedures.
Safeguards commonly include minimum match-quality criteria before any adverse decision can be considered, requirements for second-level review on high-impact findings, and detailed documentation of why a match was accepted or rejected. These practices support fairness and auditability, including in regimes that scrutinize fully automated adverse decisions. Acknowledging that some common-name or data-poor scenarios may remain ambiguous despite review, mature programs err on the side of not assigning adverse outcomes when identity linkage cannot be established with sufficient confidence and instead may seek additional evidence or alternative checks.
How do you handle India’s state-by-state workflow differences (languages, addresses, field constraints) without spiking exceptions?
C1877 India localization and exception rates — In employee BGV operations, how do you support localized workflows across Indian states (language support, address formats, field constraints) without increasing exception rates and reviewer burden?
In employee background verification operations across Indian states, localized workflows are supported by adapting language, address capture, and operational practices to local realities while keeping core verification and governance standards uniform. The objective is to improve data quality and candidate usability in diverse regions without multiplying exception rates or reviewer workload.
On the input side, organizations often provide candidate forms and instructions in prevalent local languages for blue-collar and gig segments and adjust address fields to accommodate common regional formats, including landmarks, village names, and PIN usage patterns. Field address verification instructions and templates may also be tailored so agents can record information in ways that reflect local layouts and administrative units. Despite these localizations, outcome categories for checks, discrepancy labels, and SLA definitions are usually standardized so that metrics remain comparable across states.
To keep exceptions under control, mature programs pilot localized templates in selected regions and track their impact on data completeness, discrepancy rates, and escalations. Iterative changes to field labels, validation rules, and help text are then made based on observed error patterns. Reviewer training is also localized, for example by familiarizing teams with common regional address structures and institution naming. Where state-level processes for police, court, or address checks differ, organizations document these variations in SOPs so that local operational differences do not translate into inconsistent decision standards. A common failure mode is imposing a one-size-fits-all form design that does not match local addressing or language realities, which leads to avoidable exceptions and manual clarifications.
If a candidate alleges we rejected them wrongly due to a verification exception, what evidence pack can you provide to defend the decision and process?
C1879 Defending wrongful adverse claims — In employee screening and IDV programs, how do you handle a public incident where a candidate claims a wrongful adverse decision due to a verification exception, and what evidence pack is available to defend the workflow and reviewer actions?
When a public incident occurs in which a candidate claims a wrongful adverse decision due to a verification exception, employee screening and IDV programs activate an incident response that combines transparent communication, structured fact-finding, and evidence-backed review of the workflow. The cornerstone of this process is assembling a comprehensive evidence pack that reconstructs the case from consent through final decision.
Operationally, organizations pause any further action on the disputed outcome and gather all artifacts associated with the case. These typically include the consent record, candidate-submitted data and documents, logs of checks performed across identity, employment, education, criminal or court records, and address verification, exception and escalation flags, reviewer notes or overrides, and relevant timestamps. System audit trails and access logs help demonstrate chain-of-custody by showing who viewed or changed information and when. In less automated contexts, equivalent evidence may be compiled from emails, call records, and manual logs, though this is slower and less robust.
The evidence pack serves both defensive and corrective purposes. It enables internal teams to determine whether the adverse decision reflected a process error, a misinterpreted exception, or correct application of policy, and it supports responses to auditors, regulators, or legal forums if required. At the same time, organizations use defined redressal channels to communicate findings to the candidate, correct records where mistakes are confirmed, and adjust workflows or training to reduce recurrence. A common failure mode is scattered or incomplete logging, which impedes timely and credible responses. More mature programs design their case management and governance practices so that such evidence bundles can be produced reliably whenever decisions are challenged.
How do you show that exception handling didn’t cause extra data collection or retention beyond purpose under DPDP-like rules?
C1881 DPDP-safe exception handling proof — In employee background verification operations under DPDP-style expectations, how do you demonstrate that exception handling did not lead to excess data collection or extended retention beyond purpose?
Organizations demonstrate that exception handling stayed within DPDP-style limits by binding exceptions to predefined data scopes, explicit purposes, and logged retention decisions instead of leaving these to individual reviewer judgment. The background verification workflow should treat any extra data collected under an exception as a controlled variant of the standard case, with its own fields, reasons, and timers recorded.
Mature programs define, for each exception type, which additional attributes or document categories may be requested and which are prohibited. Where platforms support it, they configure upload controls and request templates so reviewers can only ask for specific, policy-approved evidence, and every request is tagged to a purpose and consent artifact. In more manual or legacy setups, organizations compensate with reviewer playbooks, mandatory reason codes, and spot checks that compare requested documents against written DPDP-aligned policies to detect over-collection.
Retention alignment is demonstrated when the verification system or records process marks exception data with the same or shorter retention as the parent check, and records the eventual deletion or archival event. Some organizations achieve this at document level. Others use case-level timers but ensure all exception data is stored only inside the governed case container and not in uncontrolled channels. During audits, sampled exception cases should show a chain-of-custody for when extra data was requested, who approved it, when the purpose was completed, and when access was restricted or data deleted. Periodic Compliance reviews of exception logs, even if basic, provide additional evidence that exception handling has not become a backdoor for excess collection or extended retention.
If we change exception rules and reviewer productivity drops, what in-product guidance and rollback options do we have to prevent team pushback?
C1882 Preventing reviewer revolt on change — In employee BGV operations, how do you avoid a ‘reviewer revolt’ when workflows change—what change management, in-product guidance, and rollback options exist if productivity drops after a new exception rule goes live?
Organizations avoid a “reviewer revolt” during BGV workflow changes by pairing any new exception rule with structured change management, lightweight in-flow guidance, and predefined rollback or mitigation paths tied to measurable productivity indicators. The goal is to make reviewers feel that the rule is controlled, explainable, and reversible if it clearly harms operations.
Operationally, leaders brief reviewers on why the rule is changing, how it supports compliance or risk reduction, and what will be measured after go-live. Even when the platform cannot offer advanced tooltips or decision trees, teams can embed short, standardized instructions in case notes, exception reason drop-downs, and quick-reference job aids that mirror the configured decision paths. Reviewers should have an explicit feedback channel to flag confusing scenarios and emerging workarounds, which the operations manager monitors alongside metrics such as touches per case, average handling time, and escalation ratio.
Rollback and tuning options are defined in advance. Many organizations first enable new exception rules in a staging environment or for a limited subset of lines of business, then set guardrails such as acceptable ranges for manual-review volume or handle time. If these thresholds are breached, the governance group can narrow criteria, adjust thresholds, or, where compliance allows, revert to the prior configuration. Where formal SLAs or regulatory commitments limit rollback, mitigation can take the form of temporary staffing support, refined reviewer guidance, or minor rule tweaks rather than full reversal. Aligning reviewer performance expectations and KPIs to the new workflow, at least during a transition period, reduces frustration when complexity temporarily increases.
If our HR inputs are messy (wrong dates/employer names), how do you handle exceptions without creating lots of hidden cleanup work?
C1884 Exceptions from messy HR inputs — In background screening operations, how do you handle exceptions caused by mismatched HR inputs (wrong joining date, wrong employer name) without turning the vendor into the ‘data janitor’ and creating hidden operational costs?
Background screening operations handle exceptions from mismatched HR inputs by routing suspected data errors back to the client for confirmation and correction, instead of silently fixing them inside the vendor workflow. This preserves HR’s role as source-of-truth owner and prevents the verification provider from absorbing unbounded “data janitor” work.
When reviewers encounter issues such as an employer name that cannot be matched or a joining date that conflicts with evidence, they classify the problem using standardized exception reasons linked to “client data quality” rather than generic insufficiency. The verification case is then paused or flagged, and HR is notified through the agreed communication channel to validate or amend the record. In mature integrations, corrected data flows from the HRMS or ATS back into the verification system. Where such integration does not exist, HR may upload a corrected form or written confirmation, which is attached as evidence and used to resume checks.
To avoid hidden costs and delays, organizations document in operating procedures and, where possible, in contracts that core data corrections remain the client’s responsibility. They track metrics such as the count and age of cases stalled due to HR-input errors and the incremental touches per such case. Persistent high volumes of these exceptions signal the need for upstream fixes, such as better validation in HR intake forms or training for recruiters on mandatory fields. By keeping correction authority with HR but making the feedback loop structured and measurable, buyers avoid pushing unbounded, unpriced remediation work onto vendors while still resolving mismatches efficiently.
When HR pushes for speed but Compliance wants strict evidence, how do you prevent bypasses yet still hit hiring timelines?
C1885 HR speed vs compliance control — In employee BGV operations, when HR demands speed but Compliance demands defensibility, how does the exception workflow enforce non-bypassable steps (approvals, evidence requirements) while still meeting hiring deadlines?
In employee BGV operations, organizations balance HR’s speed requirements with Compliance’s defensibility by making critical exception steps structurally hard to bypass, then using risk-based policies so only a subset of cases incur that extra friction. The objective is that exceptions with real regulatory or fraud impact always carry documented approvals and evidence, while routine low-risk cases move quickly.
Concretely, high-impact exceptions such as onboarding with pending criminal checks or unresolved identity doubts are tied to mandatory fields and approvals. Where the workflow platform allows it, users cannot clear these exceptions or close the case until specific evidence types are attached and a designated approver records a decision with a time-stamped digital sign-off. In more manual environments, teams approximate this with checklists, dual-review requirements, and documented email approvals that are attached to the case record. In both models, the chain-of-custody shows who accepted which risk and on what basis.
To keep hiring deadlines realistic, organizations avoid applying maximum-friction exception handling to every situation. They classify roles or checks into risk tiers, even if only coarse, and reserve strict, multi-level exception paths for higher tiers. Lower-risk exceptions can be auto-resolved within predefined bounds or approved by frontline managers under standard templates. Shared dashboards that report time-to-hire, TAT, and exception frequency by tier allow HR and Compliance to see where controls are slowing hiring and adjust thresholds. When business leaders demand one-off accelerations, these are routed through the same exception pattern, with explicit approver identity and risk acknowledgement, rather than informal side channels.
How do you stop exception handling from becoming reviewer-by-reviewer ‘shadow policy,’ and enforce consistent rules across teams?
C1886 Preventing shadow policies in ops — In employee screening operations, how do you prevent exception workflows from becoming ‘shadow policies’ maintained by individual reviewers, and what governance controls enforce consistency across shifts and locations?
Employee screening operations stop exception workflows from becoming “shadow policies” by defining exception rules centrally, constraining how reviewers can record decisions, and regularly checking for behavioral drift across teams and shifts. The goal is that what counts as an exception and how it is resolved is determined by governance, not by individual habit.
Organizations document exception categories, triggers, and allowed outcomes in a policy owned by HR and Compliance, and then reflect that policy in the case management tooling as standardized reason codes, fixed outcome options, and predefined escalation paths. Reviewers are trained to select from these structured options rather than invent free-text rationales, and they receive quick-reference guides for common edge cases. In less configurable systems, teams still align on standard templates and checklists so that reviewers in different locations are following the same decision trees.
Governance teams then monitor consistency. Where analytics are available, they compare exception frequency and outcome patterns by reviewer, team, or site to identify outliers that may signal unofficial practices. In lower-maturity setups, supervisors or QA staff sample cases from different shifts and locations on a rotating basis to look for divergence from the documented process. Findings are fed back into training and, if needed, into refinements of the written policy or system configuration. A clear owner for exception rules, usually a joint HR–Compliance committee, ensures that any structural changes are deliberate and communicated, rather than emerging silently from frontline improvisation.
How do you prevent reviewers from over-collecting documents during exceptions just to close cases, and how do you detect it?
C1888 Preventing over-collection in exceptions — In background verification operations, what safeguards prevent reviewers from over-collecting documents ‘just to close the case’ during exception handling, and how is that behavior detected and corrected?
Background verification operations limit reviewers from over-collecting documents “just to close the case” by restricting what can be requested for each check, forcing explicit justification for extra evidence, and periodically checking whether actual behavior matches documented minimization policies. The intent is that speed incentives never override DPDP-style data minimization.
Where tooling allows, organizations configure check-specific and exception-specific document categories rather than open-ended upload buckets. When a reviewer wants additional evidence, the platform or process requires them to select a standardized reason and, if necessary, indicate the exact type of document being requested. Even when reviewers must communicate via email or messaging, guidance requires them to request only listed document types and to log the request in the case record with an appropriate reason code. Training emphasizes that over-collection creates compliance risk and is not an acceptable shortcut.
Detection and correction scale with maturity. Some teams use analytics to compare average documents per case and per exception type across reviewers and teams, flagging outliers for review. Others rely more on periodic QA sampling across different shifts or locations. In both cases, when over-collection is identified, managers respond with targeted coaching, clarification of policy, or, where necessary, added controls such as supervisor approval for certain reviewers’ extra-document requests. By combining configuration limits where possible with structured logging and targeted oversight, organizations can curb the tendency to request unnecessary documents under exception pressure.
If an exception rule is configured badly and floods us with manual reviews, what guardrails do you have to test and roll back safely?
C1891 Guardrails for exception rule changes — In employee BGV operations, what are the operational consequences of a poorly configured exception rule (for example too many manual reviews), and what guardrails exist to test, stage, and roll back changes safely?
In employee BGV operations, a poorly configured exception rule can flood queues with manual reviews, extend handling times, and either over-flag or under-flag risk, all of which threaten SLA performance and assurance quality. Organizations reduce this exposure by treating rule changes as governed releases with pre-testing, controlled rollout, and defined mitigation paths rather than ad-hoc configuration tweaks.
Before full deployment, teams test new rules against representative data. In more advanced setups, this happens in staging environments or via “shadow” execution that records how often a rule would fire without altering live routing. Where such tooling is not available, operations at least simulate impact on a sample of historical cases. The aim is to estimate manual-review volume and to check that the rule is not obviously missing known risk scenarios.
Production rollout is then limited in scope and closely monitored. Organizations may enable the rule only for certain geographies, business units, or risk tiers while tracking exception rate, touches per case, handle time, and any change in detected discrepancies. They define in advance the ranges for these metrics that are acceptable and record conditions under which the rule will be narrowed or reworked. In some situations, such as rules driven by new regulation, full rollback is not feasible, so mitigation focuses on targeted refinements, clearer reviewer guidance, or temporary staffing adjustments. Governance committees periodically review exception-rule performance to ensure that cumulative tweaks do not degrade assurance or overload operations.
On exception-heavy days, how do you reduce reviewer click fatigue, and what touch reduction per case can we realistically expect?
C1892 Click fatigue reduction expectations — In employee BGV operations, how does your workflow design reduce ‘click fatigue’ for reviewers during exception-heavy days, and what measurable reduction in touches per case should an operations leader expect after rollout?
Employee BGV workflow design reduces reviewer “click fatigue” during exception-heavy days by removing redundant interactions, grouping related actions, and automating predictable steps, while still capturing the data needed for compliance. When this is done deliberately, operations leaders can observe lower touches per case and more stable handle times under high exception load.
Design improvements often include presenting all key exception information and actions on a single screen where feasible, using standardized reason codes instead of free-text typing, and triggering multiple outcomes from one decision, such as updating status and notifying HR together. Auto-filling fields from existing case data, providing templates for common comments, and enabling bulk handling of similar low-risk exceptions further reduce navigation and manual entry. Where the platform is less configurable, teams approximate these gains through concise checklists, keyboard-friendly forms, and clear labeling that cuts down re-reading and back-and-forth between screens.
Because simplification must not erode defensibility, organizations identify which fields and evidentiary steps are mandatory for audit and ensure these remain explicit even in streamlined flows. They then baseline touches per case and handle time for exception scenarios before changes and compare them after rollout. In mature implementations, a successful redesign is reflected in reduced clicks and time per exception without an increase in error rates or missing data. Where metrics do not improve, teams iterate on layout and automation rather than assuming UX gains by default.
What’s the real-world failure rate of automated IDV checks, and how do you handle exceptions so candidates don’t drop off?
C1895 IDV automation failures and recovery — In employee screening operations, what is the realistic failure rate of automated IDV checks (OCR errors, liveness failure, selfie mismatch) and how does your exception workflow prevent this from turning into a candidate experience disaster?
In employee screening operations, automated IDV checks such as OCR, liveness, and selfie-to-ID face match inevitably produce some failures due to document quality, environment, or user errors. Exception workflows prevent these from turning into candidate experience failures by limiting how many times candidates struggle with the same step, then moving them into structured fallback paths with clear instructions and visibility for support teams.
When an automated IDV step fails, candidates should receive explicit, simple feedback and a small number of guided retry opportunities, for example with prompts on lighting, framing, or document placement. After predefined retry limits, the case transitions to an exception state rather than looping endlessly. Depending on regulatory allowances and risk policies, this exception state can trigger manual review of the captured images, offer alternative document types, or schedule assisted verification via a support channel. All such flows are designed and documented in alignment with applicable KYC or identity regulations so that fallbacks do not compromise compliance.
Operations teams then monitor how often IDV steps fail and how many cases enter these exception paths, using this data to refine UX, thresholds, or candidate guidance. HR and candidate support staff are given access to IDV status and reason codes so they can respond accurately to candidate queries and avoid confusion or repeated instructions. By bounding retries, offering policy-compliant fallbacks, and making status transparent, organizations contain the impact of automated IDV failures on both candidate experience and overall screening throughput.
How do you stop exception backlogs from hiding fraud signals like repeated resubmission loops, and what alerts trigger deeper review?
C1896 Fraud signals hidden in exceptions — In employee BGV operations, how do you prevent exception backlogs from masking fraud risk (for example, repeated ‘document resubmission’ loops), and what red-flag alerts trigger higher scrutiny?
In employee BGV operations, exception backlogs can hide fraud risk if repeated “document resubmission” cycles or long-stagnant exceptions are seen only as workload issues. Organizations reduce this risk by turning certain exception behaviors into explicit red flags and routing them into higher-scrutiny workflows.
Case tracking and analytics should distinguish between first-time submissions and resubmissions, record how many times a candidate or case has revisited a given step, and track how long exceptions stay open without progress. Policies then define thresholds that trigger alerts, such as a candidate exceeding an allowed number of resubmissions for identity or address documents, or an exception remaining unresolved past a risk-defined timeframe. When these thresholds are breached, the case is escalated to more experienced reviewers or a risk function to reassess authenticity and decide whether to request alternative evidence, add supplementary checks within program scope, or recommend rejection.
Risk teams also examine exception patterns across groups, such as clusters of similar backlogs linked to a particular recruiter, vendor, or geography, which may indicate systemic issues or coordinated attempts to game verification. Even where tooling is basic, periodic reviews of long-pending and repeatedly touched exceptions can highlight cases that warrant deeper investigation. By explicitly defining which backlog characteristics are treated as red flags and binding them to escalation workflows, organizations avoid allowing exception queues to become blind spots for fraud.
What exact audit fields do you capture for each exception (status changes, evidence viewed, timestamps, rationale) for chain-of-custody?
C1905 Exception audit trail field coverage — In employee screening operations, what practical audit trail fields are captured for every exception (who changed status, what evidence was viewed, timestamps, rationale) to support regulator-ready chain-of-custody?
Employee screening operations create regulator-ready chains-of-custody by capturing a focused set of audit trail fields for every material exception decision. These fields reconstruct who changed the case, what status changed, when it changed, which evidence was considered, and why the reviewer or approver judged the exception acceptable or not.
Typical audit records include the user ID or role of the person performing the action, the previous and new case or check status, and precise timestamps. For exceptions that influence onboarding or access decisions, organizations also link to the underlying evidence artifacts, such as identity documents, employment or education confirmations, or criminal and court record results, so that the decision can be re-evaluated in context.
To improve explainability, many programs add standardized exception reason codes plus a short free-text rationale field. For higher-risk roles, the audit trail also records secondary approvers, including HR, Compliance, or business owners, along with their decision timestamps. These fields can be stored using standard logging mechanisms, with access controls limiting who may view sensitive content, so privacy and data minimization obligations under DPDP-style laws remain respected.
Operations and Compliance teams periodically review these logs to ensure status changes align with policy and to prepare evidence packs for auditors or regulators. Well-structured audit fields make it easier to show that exceptions were not arbitrary, that they followed documented KYR and risk-tiering policies, and that individual responsibility for each decision is clearly traceable without collecting unnecessary personal data in the log itself.
How do you handle duplicate BGV cases from ATS/HRMS so we don’t do double work or get inconsistent outcomes?
C1909 Duplicate case handling SOP — In employee BGV operations, what is the operator-level process for handling duplicate cases (same candidate initiated twice via ATS/HRMS) and how do you prevent double work and inconsistent outcomes?
In employee BGV operations, duplicate cases for the same candidate are managed through a defined process that detects likely duplicates, assigns one primary case, and preserves all evidence while avoiding double work and conflicting outcomes. The process emphasizes careful matching and controlled case consolidation rather than ad-hoc cancellation.
Detection usually relies on a combination of identifiers such as HRMS or ATS candidate IDs, email addresses, and other allowed attributes, rather than any single field. SOPs instruct operators to flag suspected duplicates and halt parallel work until a decision is made. Because verification findings may evolve over time, reviewers compare both cases, including submitted documents and interim results, to confirm whether they truly refer to the same hiring event and time frame.
The authority to merge or cancel cases is typically limited to supervisors or designated admins. Once a duplicate is confirmed, one case is marked as primary, and all relevant evidence and notes from the secondary case are linked or copied to it. The secondary case is then explicitly closed as a duplicate with a clear reason code, so the audit trail shows what happened.
HR and ATS references are updated so downstream systems only rely on the primary case outcome. Operations teams track duplicate frequency and the effort spent reconciling them, using this data to improve integrations and de-duplication rules at the interface between ATS/HRMS and BGV workflows. This reduces future duplicates and maintains a consistent, auditable history per candidate.
When exceptions require extra documents, how do you enforce purpose limitation and record it in the consent ledger?
C1910 Purpose limitation for extra documents — In employee screening operations under DPDP-like requirements, how does the exception workflow enforce purpose limitation when extra documents are requested, and how is that purpose recorded in the consent artifact/ledger?
In employee screening operations under DPDP-like regimes, exception workflows enforce purpose limitation by requesting only narrowly relevant extra documents, tagging each request to a defined verification purpose, and ensuring that purpose is reflected in the consent record. The objective is to avoid turning exceptions into uncontrolled data collection while still resolving verification gaps.
When a reviewer needs additional documentation, SOPs require selection of a specific purpose category aligned to the underlying check, such as address verification, identity clarification, or employment history confirmation. This choice constrains what may be requested and stored. Reviewers are trained to ask for the minimum document necessary to resolve the issue rather than broad, multi-purpose records, which supports data minimization.
Consent artifacts, whether implemented as structured ledgers or well-documented forms, should describe the categories of data and purposes that cover both routine and foreseeable exception scenarios. If handling an exception requires a type of document or purpose that falls outside the original scope, organizations present a concise additional notice explaining why the new document is needed and how it will be used. Where checks are mandatory for hiring or regulatory reasons, the communication clarifies that declining to provide the document may halt or delay onboarding, rather than framing consent as purely optional.
For each exception, operations teams link the request to the applicable consent text and record key metadata such as purpose category and timestamp. This linkage demonstrates in audits that extra documents were collected for a defined KYR purpose, within a limited scope, and not repurposed beyond the employment verification context.
How do you measure manual touches per case across exception types, and how do you prevent teams from gaming it?
C1912 Manual touches measurement and gaming — In employee BGV operations, what is the practical approach to measuring ‘manual touches per case’ across exception types, and how do you prevent teams from gaming the metric?
Employee BGV operations measure ‘manual touches per case’ by counting discrete human actions on a case that materially change its state or content, then analyzing these counts by exception type and risk tier. The intent is to quantify how exceptions drive manual effort without turning the metric into an isolated performance target.
Organizations first define what constitutes a touch for their environment, typically including actions such as updating a status, adding a note or document, or sending an exception communication. Passive views without changes are often excluded to keep the measure focused on work performed. Activity logs in case management tools, or structured trackers where tools are basic, are then used to tally touches per case.
Reports segment this metric by check type, exception category, and role tier so teams can see, for example, that address exceptions in gig hiring require far more touches than straightforward identity verifications. These insights inform where clearer candidate instructions, simpler flows, or automation could reduce effort.
To limit gaming, organizations avoid tying individual incentives solely to low touch counts. Instead, they review touches in conjunction with quality indicators such as re-open rates, escalation ratios, TAT distributions, and QA findings. If touches fall while error rates or escalations rise, leaders investigate whether SOPs or reviewer behavior have changed in undesirable ways. Sampling of cases and regular governance reviews help ensure that improvements in touches per case reflect genuine efficiency rather than rushed handling.